
基于知识蒸馏的小规模遥感影像场景分类网络模型训练方法
撰写于 2018-09-29 修改于 2019-04-16 分类 遥感影像分类
Training Small Networks for Scene Classification of Remote Sensing Images via Knowledge Distillation 链接 · PDF
Chen G, Zhang X, Tan X, et al.
Remote Sensing 2018, 10(5), 719.SCI
场景分类是遥感图像分析领域中的一项基本任务,其目的是识别遥感影像图斑的土地覆盖类型。基于深度神经网络的算法(如VGG-Net、ResNet、DenseNet)在场景分类中得到了广泛的应用,并取得了显著的性能,但以上深度模型方法会消耗大量的计算资源与训练时间,不适用于嵌入式设备或星上处理等特殊情况。因此,本文将目前主流的模型压缩方法——知识蒸馏框架引入遥感影像场景分类任务中,以提高小规模网络模型的分类水平。知识蒸馏方法关键在于,使小规模的学生模型的高温softmax输出与大规模的教师模型对应的高温输出相匹配。本文在四个公开的遥感场景分类数据集(AID数据集、UCMerced数据集、NWPU-RESISC数据集和EuroSAT数据集)展开实验,以评估知识蒸馏训练方法的性能。结果表明,本文方法在四个数据集上不同程度地提高了小规模网络模型的分类水平。此外,本文还探究了当数据集样本数量较少或类别不平衡等情况下学生模型的表现,进一步验证知识蒸馏方法在低分辨率遥感影像、遥感地物类别较多、遥感影像数量较少等情况下的适用性与可行性。
1. 简介
随着遥感技术的快速发展,大量算法被提出用于自动化处理大规模的对地观测数据。场景分类作为遥感影像处理的基本任务之一,用以识别遥感影像图斑的土地覆盖类型,在众多遥感应用如土地覆盖利用调查、农业、林业与水文等都有着重要的意义。
近年来,深度学习技术,特别是卷积神经网络(CNNs)模型,在图像识别、语音识别、语义分割、目标检测、自然语言处理等领域中均表现出优异的性能。计算机视觉(CV)领域中的许多经典的深度学习模型被验证能有效应用于遥感影像场景分类任务中。区别于依赖手工特征提取的浅层模型和初级方法,深度卷积网络可通过从大型训练数据集中学习深度视觉特征来处理更复杂的场景并获得更高的准确度。
然而,深层卷积神经网络包含更多的训练参数,它们在训练和预测上需要花费更多的计算资源与时间,不适用于应用在嵌入式设备或在轨处理等特定情况下。相比之下,规模小而浅层的模型速度快,占用空间小,直接利用样本数据训练不足以得到准确的结果。
在这种情况下,学界提出了模型压缩技术,用来小型化大型深度学习模型。模型压缩技术通过学习性能更好但规模更大的模型,或通过简化深层网络模型的结构来改进浅层模型的性能。主流的模型压缩技术可分为以下三类:网络修剪,网络量化和师生训练(TST)。网络修剪,通过去除基于特定标准下不太重要的神经元或权重来减小网络规模;网络量化试图降低权重或特征的精度;师生训练方法通过学习某些特定层的分布或输出,将教师模型的知识传授给学生模型1。
知识蒸馏(KD)是一种师生训练方法。知识蒸馏方法关键在于,使小规模的学生模型的高温softmax输出与大规模的教师模型对应的高温输出相匹配。在本文中,我们首次将知识蒸馏引入到遥感场景分类中,以提高小型和浅层网络模型的性能。然后,我们对几个公共数据集进行了实验以验证知识蒸馏的有效性,并进行定量分析以探索最佳的参数设置,同时还将讨论知识蒸馏在不同类型数据集上的性能。此外,我们测试了在没有某种类型的训练样本或缺乏足够的训练数据集的情况下学生模型是否仍然可以从教师模型中提炼知识。
2. 方法
2.1 师生训练方法
师生训练方法(TST)是主流模型压缩方法之一。在师生训练中,规模较大的预训练模型被视为教师模型,未经训练的规模较小的模型视作学生模型。学生模型不仅从真实样本中进行学习,而且还将其输出与教师模型的输出相匹配。这是因为softmax层的输出(软目标)包含的信息多于单标记的训练样本(硬目标)。一般的师生训练过程首先直接在数据集上训练规模较大的模型,然后通过使用小批量随机梯度下降(MSGD)方法最小化损失函数来训练学生模型。
除了以上方法外,该领域还提出了其他师生训练的方法。Huang. Z提出了在两个网络之间匹配神经元选择性模式(NST)分布的想法,通过最小化最大均值差异(MMD),并设计新的损失函数以匹配这些分布。FitNet通过学习教师模型隐藏层的分布,将宽网和浅网络压缩成更薄但更深的网络。Yim提出传递从网络层与层之间提取的知识,计算特征之间的内积并生成到FSP矩阵中。Chen. T通过将知识从网络传输到新的更大的网络来加速对更大网络的训练。Lopez-Paz, D.将知识蒸馏与特权信息结合起来,推导出一种广义知识蒸馏。
2.2 知识蒸馏框架
2.2.1 来源于概率分布间的知识
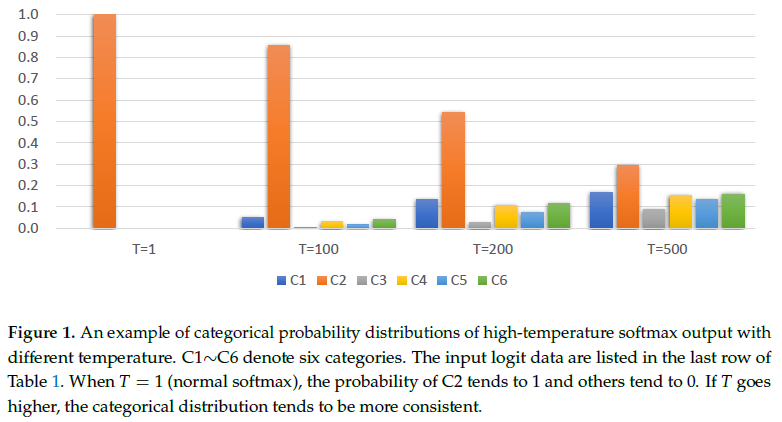
一般情况下的softmax输出为一个只有0/1值的向量,此时温度值T为1。随着温度值逐渐增大,各类的类别概率分布趋向一致,如图1所示,此时其他类别的概率分布信息可以为训练提供额外的监督信息。知识蒸馏方法不仅利用地面真实数据对学生模型进行训练,还实现了从教师模型的高温softmax输出获取有用的类别信息,提高学生模型的分类水平。
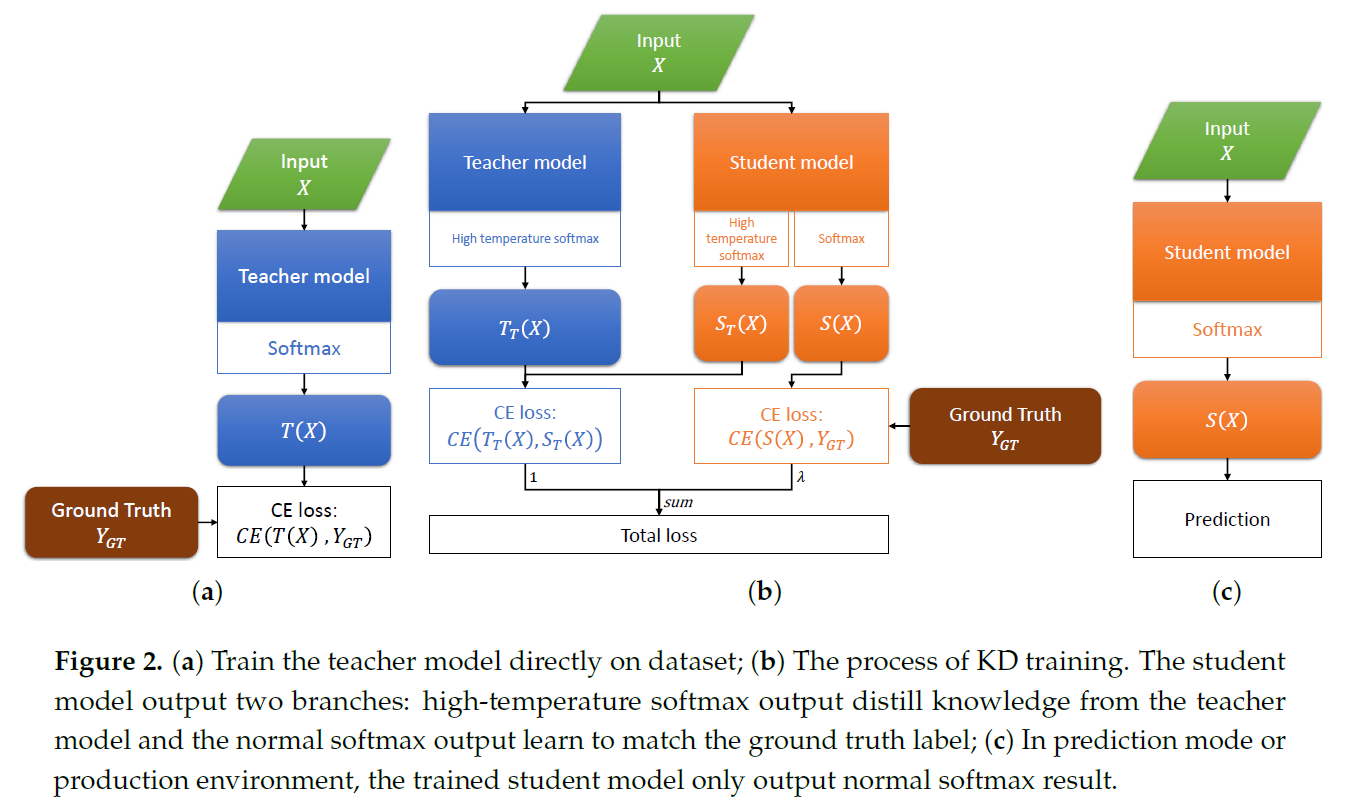
2.2.2 知识蒸馏训练流程
知识蒸馏实验流程如图2所示:
- 首先利用数据对大规模的教师模型进行训练,保留训练效果最好的模型;
- 利用教师模型的高温softmax输出和地面真实数据分别与小规模学生模型的高温softmax输出和一般softmax输出进行匹配,训练学生模型并保留训练效果最好的模型;
- 最后利用已训练的学生模型输出一般softmax结果进行分类。
3. 实验结果与分析
本文利用四个公开的遥感影像场景分类数据集(AID数据集、UCMerced数据集、NWPU-RESISC数据集、EuroSAT数据集)开展知识蒸馏实验,以验证知识蒸馏方法在遥感影像场景分类任务中的适用性与可行性。本文在实验中引入了OA(Overall accuracy)、K(Kappa coefficient)、P(Precision)、R(Recall)、F1(F1-score)和FPS(Frames per second)作为实验结果的评定指标。
3.1 在AID数据集上的实验
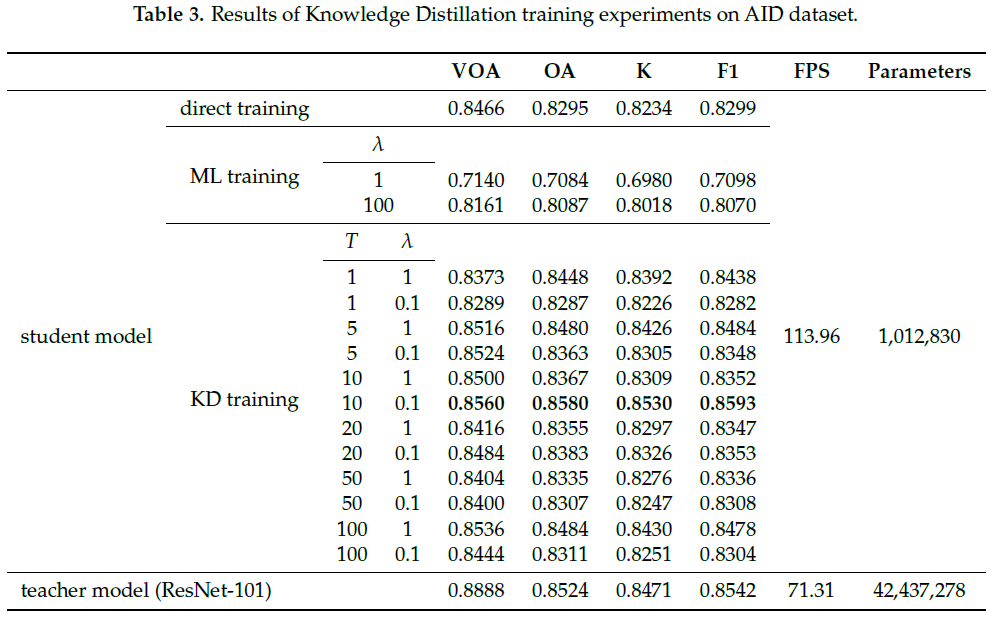
本文首先在AID数据集上开展实验,验证知识蒸馏方法的适用性,并探究了温度值(T)与损失比重值(Lambda)对精度的影响,结果如表3所示。
实验进一步地验证了知识蒸馏方法在只有少量数据的情况与缺乏一类数据的情况下,依旧能提升学生模型的分类水平。结果如表4与表5所示。
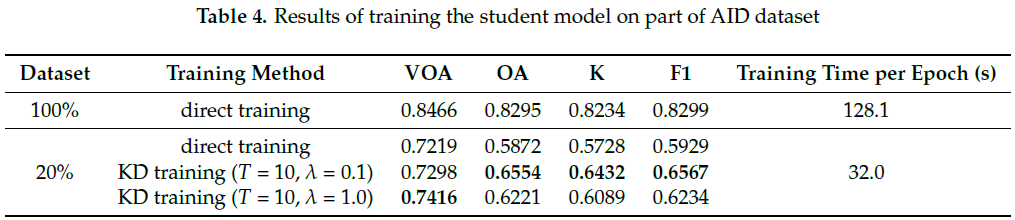
从表4可以得出,小数据集可以缩短训练时间,但训练结果较差,但在这种情况下,KD训练仍比直接训练效果更好。
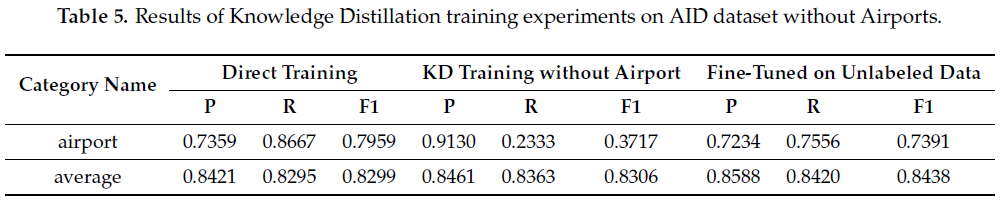
从表5来看,在没有“机场”样本的情况下,KD训练过程仍然比完整数据集的直接训练获得更好的F1值。从蒸馏模型的角度来看,在训练时从未见过“机场”样本。然而,它具有高精度,与低召回率。如果我们通过知识蒸馏继续微调学生模型上未标记数据,机场的F1值可从0.3717增加到0.7391。
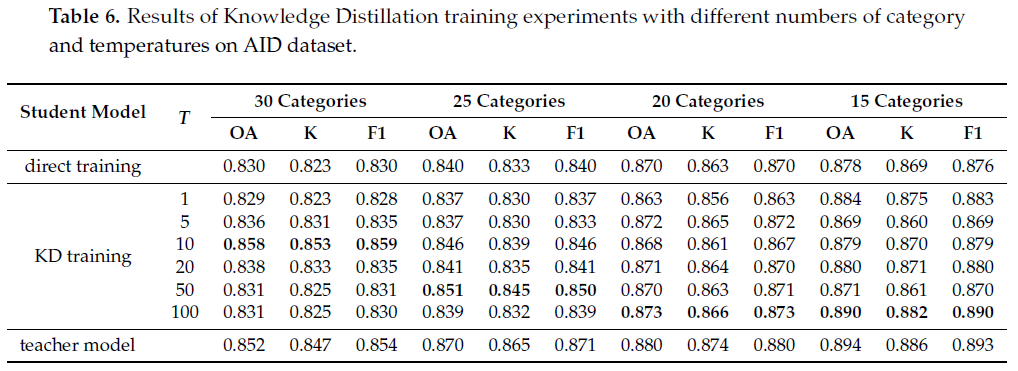
在AID数据集上,本小组还探究了场景类别数与最优温度值的关系。结果如表6所示,随着数据集类别数的减少,学生模型达到最佳分类水平的最优温度值逐渐增大。
3.2 在其他数据集上的实验
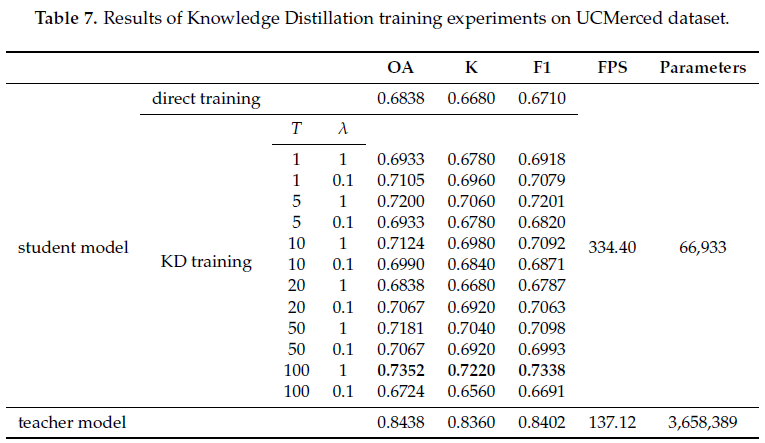
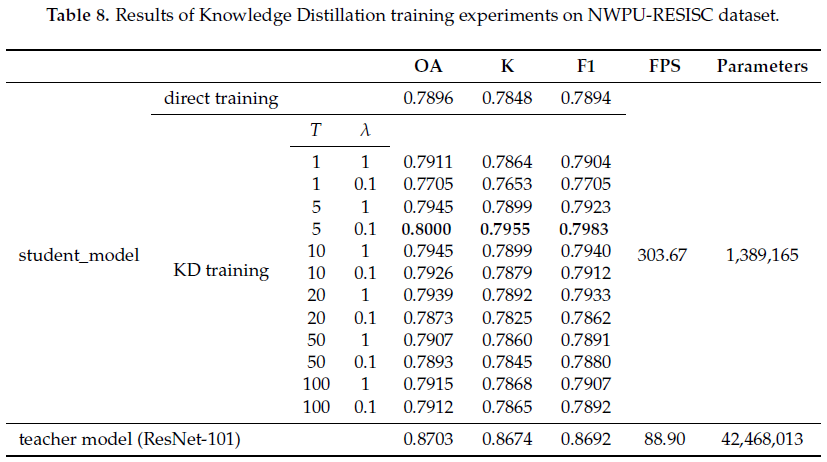
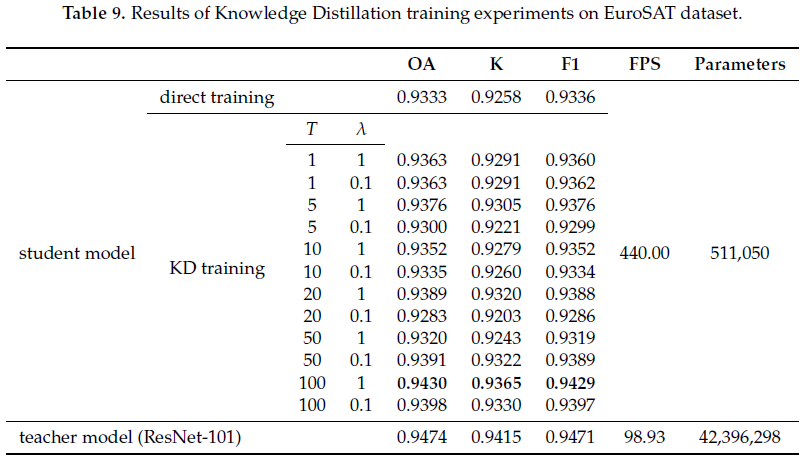
本文还在UCMerced数据集、NWPU-RESISC数据集、EuroSAT数据集三个数据集上进行实验,进一步验证知识蒸馏方法在低分辨率遥感影像、遥感地物类别较多、遥感影像数量较少等情况下的适用性与可行性,结果如表7-表9所示。
4.结论
综合以上实验结果,可见知识蒸馏方法在遥感影像场景分类任务中具有可行性,可有效地提高小规模网络模型的分类水平。
如何引用本文:
1 师生训练方法易与迁移学习相混淆。在迁移学习中,我们首先在某个数据集上训练基础模型,然后将学习到的特征转移到另一个目标网络,以便在不同的数据集和任务上进行训练。