
一种基于卷积神经网络(CNN)的高分辨率遥感影像分类方法
撰写于 2018-09-28 修改于 2019-04-16 分类 遥感影像分类
An object-based supervised classification framework for very-high-resolution remote sensing images using convolutional neural networks 链接
Zhang X, Wang Q, Chen G, et al.
Remote Sensing Letters. 2018, 9(4): 373-382.SCI
基于对象的影像分类方法(Object-based image classification,OBIC)是针对高分辨率(very-high-resolution,VHR)遥感影像分类方法中基于像素的图像分类(pixel-based image classification,PBIC)的不足而提出的,然而,OBIC中的大多数分类方法都是处理从分割影像对象中提取的一维特征。为了提取分割对象的二维深度特征,本文采用卷积神经网络(CNNs),提出了一种新的深度OBIC框架。首先分析了分割对象的不同掩码策略,并设计了两种网络架构。对比实验结果表明,DiCNN-4(Double-input CNN)在实验数据集上获得了比传统OBIC方法更高的整体精度(OA)、Kappa系数和F1测度。
1、简介
基于对象的图像分类(OBIC)已经成为超高分辨率遥感影像土地利用的主流框架。OBIC可以利用高分辨率遥感影像中的纹理、空间几何信息,与基于像素的图像分类(PBIC)框架相比,在一定程度上克服了“椒盐”现象。常见的OBIC框架包括以下步骤:
- 图像预处理
- 图像分割
- 特征提取
- 监督分类
OBIC中的大多数分类方法都是处理从分割对象中提取的手工制作的特征,包括光谱特征,空间特征,纹理特征和其他经典光谱植被指数(vegetation indices, VI),如归一化差异植被指数(Normalized Difference Vegetation Index, NDVI)和归一化差异水指数(Normalized Difference Water Index, NDWI)。只有少数研究专注于自动特征提取方法,如稀疏编码和堆叠去噪自动编码器。然而,这些无监督的一维特征是从二维数据中提取的,这导致了对象信息的丢失和泛化的难度。
为了提取对象的二维深度特征,本文将有监督的卷积神经网络(CNN)引入到OBIC框架中。文献1还提出了一种混合OBIC框架,该方法结合了手工和深度CNN提取的特征。然而,该方法并不直接处理分割对象。与这个想法不同,我们将整个分割对象输入到CNN网络中,并且仅利用CNN提取的特征。本文的贡献如下:
- 首次将CNNs引入到OBIC框架中,直接从分割对象的原始图像块中提取二维深度特征。
- 提出了两种裁剪策略来对框架中的分割对象进行预处理。
- 设计了两种CNN模型架构,同时处理分割对象的图像数据和掩码数据
2、方法
在本节中,我们首先探索处理分割对象掩膜(mask)的方法,并将其转换为适合CNNs的输入。同时,我们设计了CNN的两种架构来提取深度二维特征进行分类。
2.1 分割对象预处理
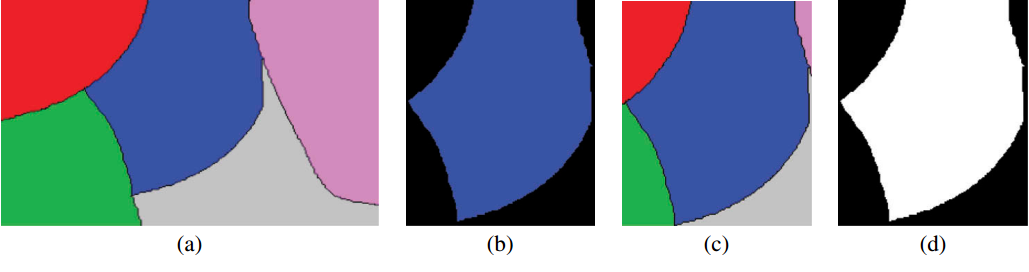
分割后的输入图像被裁剪成不同形状和尺度的分割对象。因此,需要对分割对象的边界(形状)和原始栅格数据进行预处理,以满足CNNs的要求。这意味着输入图像的大小必须是固定的。在这种情况下,我们提出以下两种裁剪策略:
- 用最小外接矩形裁剪分割对象,将原始像素值保留在对象的边界内,并在边界外用零(黑色)填充像素(图1(b))
- 创建两种类型的数据源。第一个是原始裁剪的分割对象patch(图1(c))。另一个是分割对象的二进制掩码,边界内为零填充,外部为一填充(图1(d))
2.2 影像分类网络结构
根据2.1中提到的两种裁剪方法,我们为OBIC设计了两种CNN架构:单输入CNN(single-input CNN, SiCNN)和双输入CNN(double-input CNN, DiCNN)。SiCNN只包含一个输入数据源,而DiCNN包含两个。它们都由几个基本的CNN层组成:卷积层、最大池化层、全连接层、修正线性单元(ReLU)激活层、全局平均池化(GAP)层和softmax输出层。它们之间的区别在于不同的输入数据源和网络分支架构,具体结构如下图:
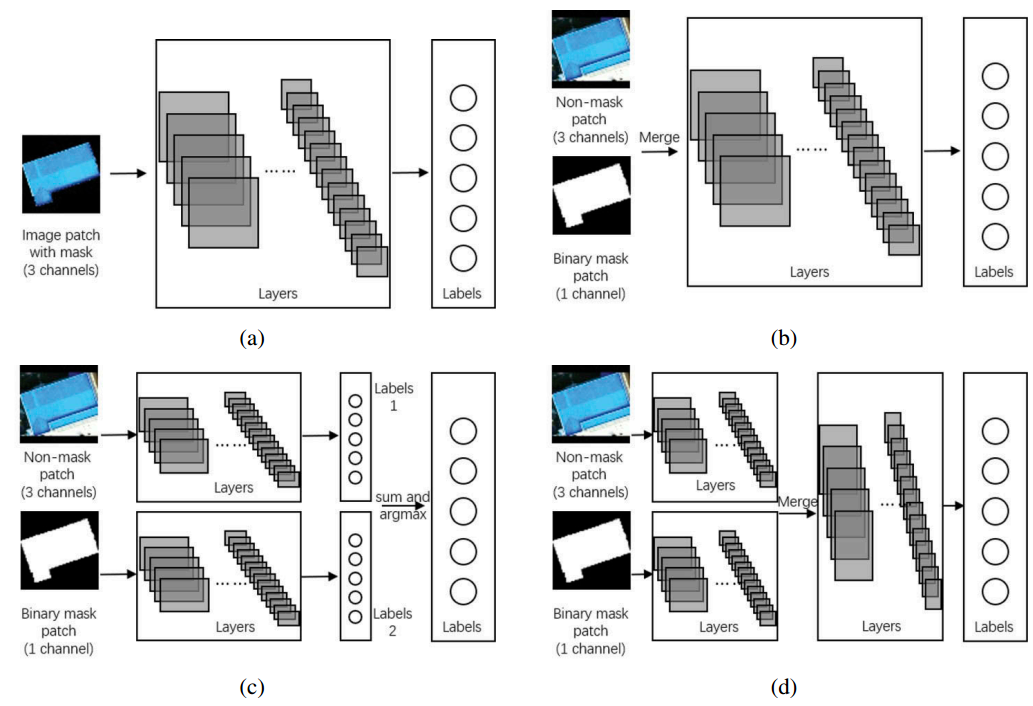
- 图2(a): SiCNN-3,以裁剪对象的三通道(RGB)patch作为输入(图1(b))
- 图2(b): SiCNN-4,输入是每个裁剪对象的无掩码图像patch和二进制mask的组合,总共包含四个通道(RGB图像+二进制mask)
- 图2(c): DiCNN-a包含两个完整的CNNs,分别从图像和掩码中学习特征并进行预测,然后对各网络的预测进行求和,最后用argmax方法进行预测。
- 图2(d): DiCNN-b也包含两个独立学习特性的CNNs。然而,它是对提取的特征进行合并,然后另一个CNN将学习这些合并的特征并做出最后的预测。
3、实验
3.1 数据集和实验设计
本节对2013年中国安徽无人机采集的VHR图像数据集进行实验(图3)。数据集的空间分辨率为0.5m和大小是10595×9748像素。数据包含三个光谱波段(红、绿、蓝)。本文的目的是对图像中建筑、裸地、道路、绿地和水进行正确分类。
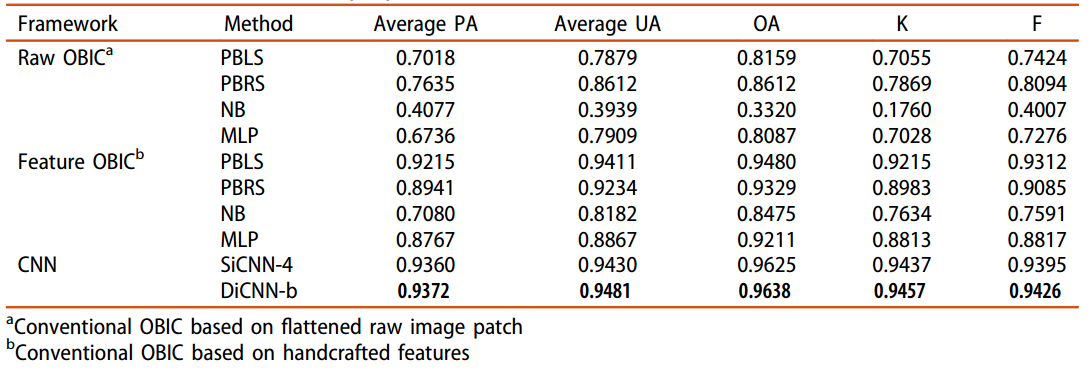
在实验中,首先对原始图像进行了正确的预处理,然后使用基于图论的最小生成树分割算法2 3进行影像分割。我们随机选取其中7093个作为训练样本,1520个作为验证样本,1521个作为测试样本。样本的分类分布如表1所示。我们采用总体精度(OA)、精度(precision, PA),召回率(recall, UA),κ系数(Kappa系数)和F-measure(F测度)作为精度评价指标。

3.2 SiCNNs和DiCNNs分类结果
我们在数据集中训练了上文提出的SiCNN-3、SiCNN-4、DiCNN-a和DiCNN-b网络模型。每个类别和总体分类结果如表2所示。
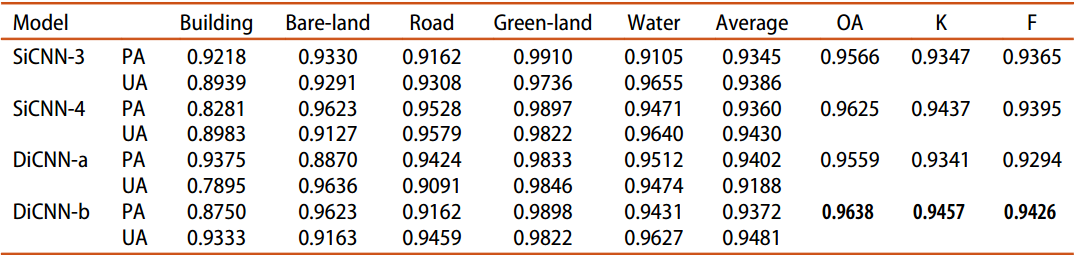
结果表明:在四种模型中,DiCNN-b具有最优的性能。此外,SiCNN-4和DiCNN-b都比SiCNN-3有更好的性能,说明增加分割对象外的信息(二值掩膜)可以提高分类结果。
3.3 与传统OBIC方法比较
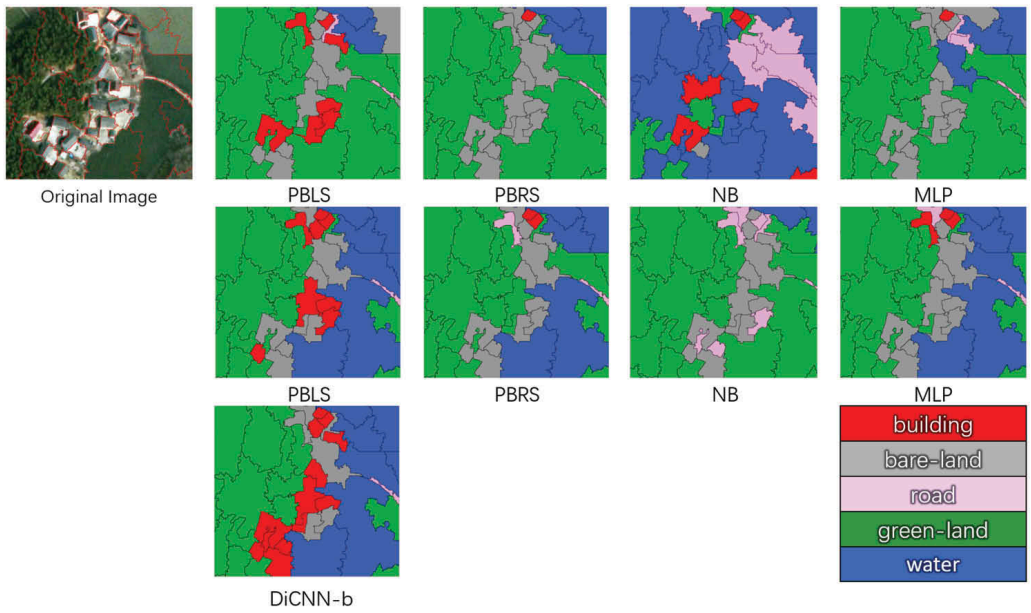
本小节对比了本文所提出的模型和传统的OBIC方法。传统的OBIC方法分为两类算法:一类将分割对象原始图像块直接作为输入;另一类是利用从分割对象提取出来的一维手工特征。具体结果如表3所示,样本标记结果如图4所示。
4、结论
本文提出了一种新的基于监督深度CNN的OBIC框架来处理由图像分割算法分割的分割对象。然后介绍了框架中的两种掩码策略和四种网络模型。实验结果表明,与其他模型和传统的OBIC框架相比,DiCNN-b模型在大数据集中的性能更好,而SiCNN-3在小数据集中的性能更好。
如何引用本文:
1 Zhao, W., S. Du, and W. J. Emery. 2017. “Object-Based Convolutional Neural Network for HighResolution Imagery Classification.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing PP 99: 1–11.
2 Felzenszwalb, P. F., and D. P. Huttenlocher. 2004. “Efficient Graph-Based Image Segmentation.”International Journal of Computer Vision 59 (2): 167-181.doi:10.1023/B:VISI.0000022288.19776.77.
3 Cui, W. 2010. “Research on Graph Theory Based Object Oriented High Resolution ImageSegmentation.” PhD diss., Wuhan University.