
基于 Double Multi-Scale Feature Pyramid Network (DM-FPN) 的高分辨率遥感影像地理空间目标检测
撰写于 2019-04-02 修改于 2019-04-16 分类 遥感影像目标检测
Geospatial Object Detection on High Resolution Remote Sensing Imagery Based on Double Multi-Scale Feature Pyramid Network 链接 · PDF
Zhang X, Zhu K, Chen G, et al.
Remote Sens. 2019, 11(7), 755; doi:10.3390/rs11070755.SCI
高分辨率遥感影像目标检测在图像自动判读领域引起了广泛的关注。基于区域的卷积神经网络(R-CNN)在该领域得到了广泛的推广,它首先生成候选区域,然后对这些区域中存在的目标进行精确的分类和定位。然而,图像尺寸过大、图像背景复杂、训练样本大小和数量分布不均匀使得检测任务更加具有挑战性,特别是对于小而密集的目标。为了解决这些问题,本文提出了一种有效的基于区域的高分辨率遥感影像目标检测框架——双多尺度特征金字塔网络(Double Multi-scale Feature Pyramid Network,DM-FPN)。DM-FPN由多尺度区域提议网络(Region Proposal Network,RPN)和多尺度目标检测网络组成,这两个模块共享卷积层,实现端到端的训练。为了增加训练数据的多样性,克服输入图像的尺寸限制,我们提出了几种多尺度训练策略。我们还提出了多尺度预测和自适应类别非极大值抑制(adaptive categorical non-maximum suppression,ACNMS)策略以提高检测性能。在大规模遥感影像目标检测数据集DOTA上的大量实验和综合评价表明了该框架的有效性,DM-FPN在验证数据集的平均精度均值(mAP)为0.7927,在测试数据集上达到了最高的为0.793。
1. 简介
高分辨率光学遥感影像目标检测越来越受到人们的重视。它不仅需要识别对象的类别,还需要给出对象的精确位置。随着对地观测技术的提高和遥感平台的多样化,遥感影像数量急剧增加,促进了对目标检测的研究。然而,图像尺寸过大、图像背景复杂、训练样本的大小和数量分布不均、光照和阴影等问题使得检测任务更具挑战性和意义。
近年来,在人工智能领域兴起的深度学习算法是一种全新的计算模型,它能够从海量数据中提取高级特征,进行高效的信息分类、解译和理解。深度学习已成功地应用于机器翻译、语音识别、增强学习、图像分类、目标检测等领域。甚至在某些应用中,已经超出了人类的水平。与传统的目标检测和定位方法相比,基于深度学习的方法具有较强的泛化能力和特征表达能力。它通过学习大量数据的特征,建立相对复杂的网络结构,充分利用数据之间的关联,构建功能强大的检测器和定位器。卷积神经网络(Convolutional neural network,CNN)是受到生物视觉认知(局部视野)启发而专门设计的一种针对二维结构图像的多层感知器,它可以逐层学习图像的深层特征。CNN的局部感知视野可以有效地捕捉到目标对象的空间位置关系。权值共享的特点大大降低了网络的训练参数和计算成本。因此,基于CNN的图像自动解译方法得到了广泛的应用。
在目标检测领域,随着大型公共自然图像数据集(如Pascal VOC、ImageNet)的发展以及图形处理器(GPU)计算能力的提高,基于CNN的目标检测框架取得了显著的成果。现有的基于CNN的目标检测方法大致可以分为两大类:region-based目标检测方法和region-free目标检测方法。Region-based目标检测方法首先生成候选区域,然后对这些区域中存在的目标进行精确的分类和定位。这些方法具有较高的检测精度,但速度较慢,主要包括Region-based CNN(R-CNN),Spatial Pyramid Pooling Network (SPP-Net),Fast-RCNN, Faster R-CNN,Feature pyramid network (FPN)等。反之,region-free目标检测方法直接对图像中多个位置的目标坐标和目标类别进行回归,整个检测过程为一个阶段。这些region-free方法检测速度较快,但精度相对较差,主要包括Over-Feat, You only look once (YOLO)和 Single shot multi-box detector (SSD)等。
基于CNN的自然影像目标检测已经取得了很大的进展,但对遥感影像进行高精度、高效率的目标检测还有很长的路要走。与自然影像不同,遥感影像通常具有以下特点:
- 观测视角不同。遥感图像通常采用自上而下的方式获取,而自然图像可以从不同的角度获取,这极大地影响了物体在影像上的渲染方式;
- 影像尺寸过大。遥感影像的尺寸和覆盖范围通常比自然影像大。与自然影像处理相比,遥感影像处理更耗时、占用内存更大;
- 类别不平衡。不平衡主要包括类别数量和目标大小。自然场景影像中的物体一般是均匀分布的,且影像通常不会包括很多物体,但是单张遥感影像可以包含一个物体或数百个物体,也可以同时包含操场等大型物体和汽车等小型物体;
- 额外的影响因素。与自然场景影像相比,遥感影像目标检测受光照条件、图像分辨率、遮挡、阴影、背景和边界锐度的影响。
针对上述问题,本小组提出了一种同时充分利用语义特征和空间分辨率特征的双多尺度特征金字塔网络(Double Multi-scale Feature Pyramid Network, DM-FPN)。同时提出了多尺度训练、预测和自适应类别非极大值抑制策略。
2. 框架方法
2.1 网络框架
基于FPN网络,本文所提出的DM-FPN框架总体结构如图1所示:
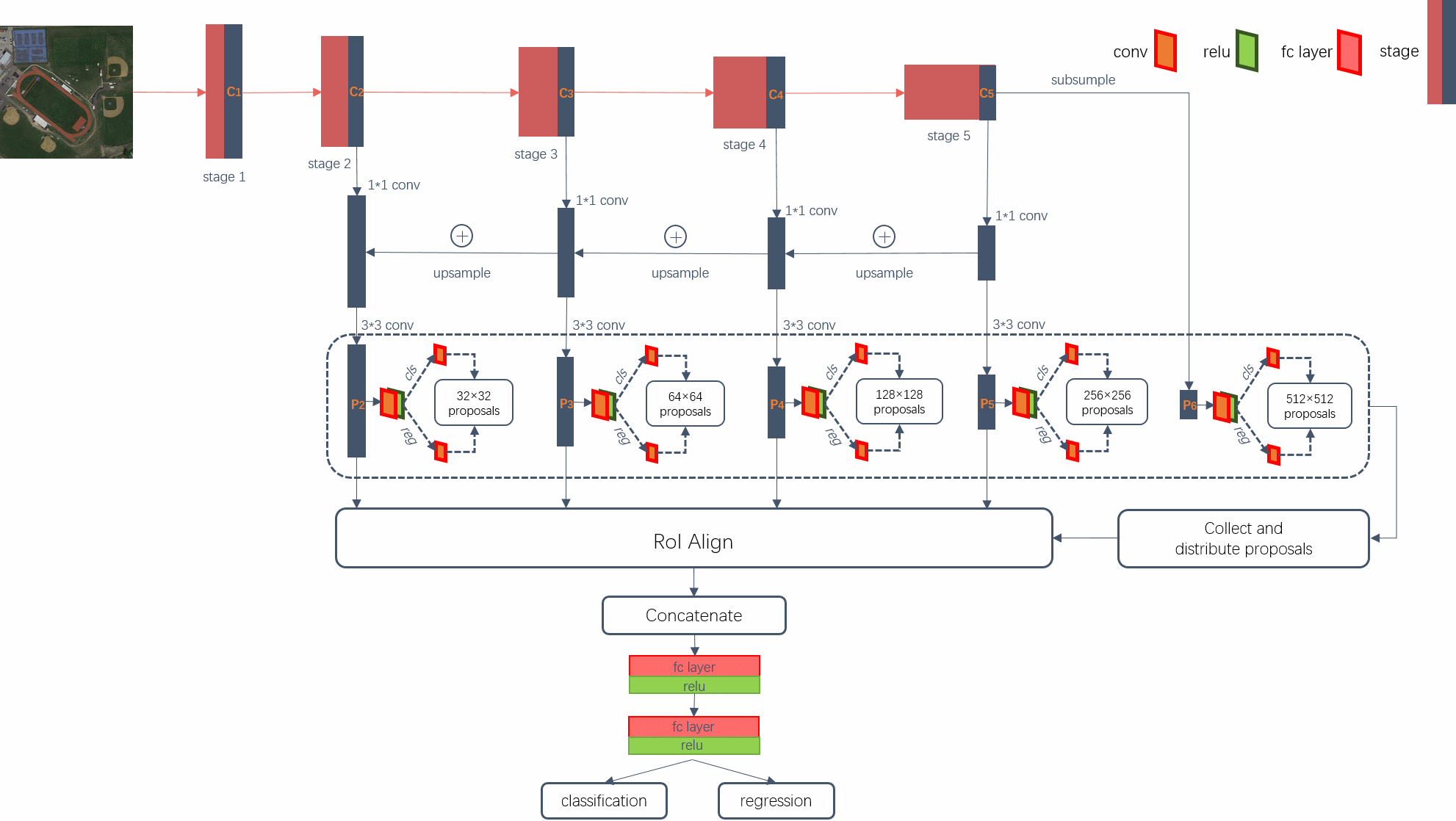
DM-FPN同时结合了弱空间分辨率、强语义特征和高空间分辨率、弱语义的特征,在检测小目标方面具有很大的优势。我们采用ResNet50作为框架的基础网络。卷积可分为5个阶段,每个阶段的最后一个残差块的输出为{C2, C3, C4, C5},它们的步长分别为{4,8,16,32},与原始图像对应。我们没有采用第一阶段C1,因为它占用很大的内存。通过FPN网络的自顶向下路径、横向连接和融合得到相应的{P2, P3, P4, P5}。实际上,为了消除上采样的混叠效果,对每个合并后的特征图进行3×3卷积,得到最终的特征图{P2, P3, P4, P5},这些特征图由RPN网络和目标检测检测网络共享。
2.2 多尺度训练策略
多尺度训练策略主要包括基于图块的多尺度训练数据和训练过程中使用的多尺度图像尺寸。其描述如下:
- 基于图块的多尺度训练数据。由于输入影像的尺寸限制,在深卷积层中会丢失大量的语义信息,特别是对于小目标来说。因此,我们将遥感影像分割成具有一定重叠度的图块,然后将这些图块送入到网络中进行训练。同时,考虑到遥感影像上的物体分布不均匀,可能包括操场等大尺寸目标,也可能包括汽车等小尺寸目标,我们分别将遥感影像放大2倍、缩小0.5倍。放大后的遥感影像增强了小目标的空间分辨率特征,而缩小后的遥感影像将大目标完整地分割到单个图像块中进行训练。
- 训练过程中使用的多尺度图像尺寸。为了增强目标的多样性,我们在训练过程中采用了多尺度的图块。每个尺度是一个图块最短边的像素大小,网络对每个训练样本随机选择一个尺度进行训练。
2.3 多尺度预测策略
在预测过程中,我们通过缩放图像来尽可能多地检测目标,缩放处理包括放大、缩小、水平翻转以及垂直翻转影像。具体来说,我们首先对每一幅测试图像进行多尺度处理,然后根据影像大小将其分割成具有一定重叠度的图块,并对这些图像块进行检测。最后,我们将自适应类别非极大值抑制应用于每一个图块以获得最终结果。
2.4 自适应类别非极大值抑制策略
非极大值抑制(Non-Maximum Suppression,NMS)是目标检测框架中的一个后处理模块,主要用于删除高度冗余的目标框。一幅遥感影像可能包含一个大的目标,也可能包含数百个小的目标,因此在不同的类别之间存在着类别不平衡。在以往的多类目标检测工作中,不同类别的NMS阈值是相同的,但是我们发现基于类别密集度(category intensity,CI),不同类别的物体设置不同的NMS阈值在一定程度上可以提高目标检测的准确性。我们将CI定义为:
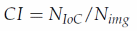
其中Nioc表示每个类别标注的样本个数,Nimg表示图像总数。如果某一类别的CI大于给定的阈值,则将该类别的NMS值设为比一般NMS阈值更大的值。通常,对于密集度较大的目标其NMS阈值更大,因为它们彼此重叠的情况更常见。
# 3. 实验
为了评估该框架的有效性,我们在DOTA数据集上进行实验。实验包括内部对比实验和外部对比实验。内部对比实验(相同的框架,不同的策略)证明了我们所提出的策略的有效性,而外部对比实验(不同的框架)证明了我们的框架的有效性。此外,我们还将基于测试数据集的结果提交到DOTA评估服务器进行评估,DM-FPN取得了最好的检测结果,尤其是在检测小而密集的目标方面。
## 3.1 数据描述
DOTA是一个用于航空影像目标检测的大规模数据集,共包含2806张影像,其中1411张训练集影像,458张验证集影像,937张测试集影像。这些图像来自不同的传感器和遥感平台,尺寸从800×800到4000×4000像素不等。DOTA由飞机(plane)、船舶(ship)、储罐(storage tank)、棒球场(baseball diamond)、网球场(tennis court)、篮球场(basketball court)、操场(ground track field)、港口(harbor)、桥梁(bridge)、大型车辆(large vehicle)、小型车辆(small vehicle)、直升机(helicopter)、转盘(roundabout,)、足球场(soccer ball field)、游泳池(swimming pool)等15大类组成。数据集共包含188,282个标注实例,每个实例都使用一个任意四边形来标记。DOTA包含两个检测任务。任务1使用原有的任意方向包围框作为ground truth。任务2使用转换后的水平边界框作为ground truth。本文中,我们只专注于使用(xmin, ymin, xmax, ymax)格式的水平包围框检测任务,因此我们需要将标记的任意方向包围框转换为每个目标的最小外包矩形。
## 3.2 内部对比实验
内部对比实验验证了多尺度训练、预测和ACNMS策略的有效性。多尺度训练和预测策略可以表达如下:
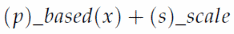
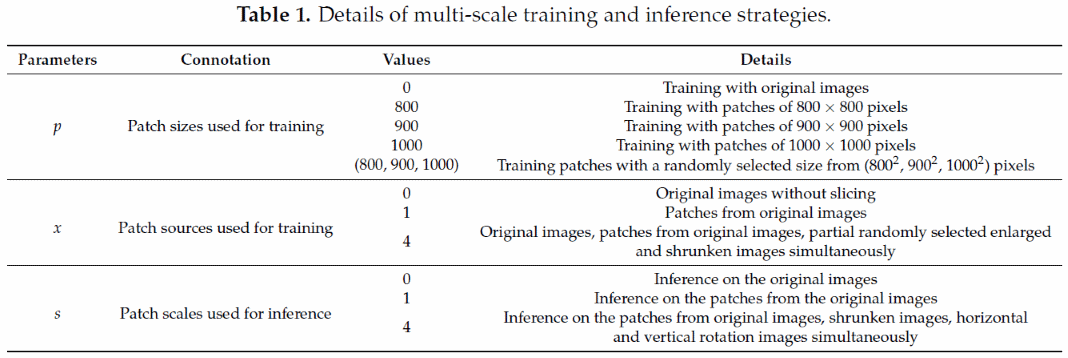
其中 p 表示用于训练的图块大小, x 表示用于训练的图块数据来源, s 表示用于预测的图块尺度。例如,800_based(4)+1_scale意味着我们将分割后的图块缩放为800×800像素进行训练。这些多尺度训练数据包括四个数据源,分别是原始图像、由原始图像、放大和缩小的图像获取的图块。在预测过程中,我们只对由原始图像得到的图块进行检测。这些预测图块的大小为1000×1000像素,重叠为200像素。最后,我们将基于每个图块检测得到的结果结合起来,采用ACNMS得到最终的结果。表1给出了多尺度训练和预测策略的详细说明:
3.2.1 基于图块的训练和预测策略对比实验
我们实施两组对比实验来验证基于图块的训练和预测策略的有效性。实验结果如表2所示:
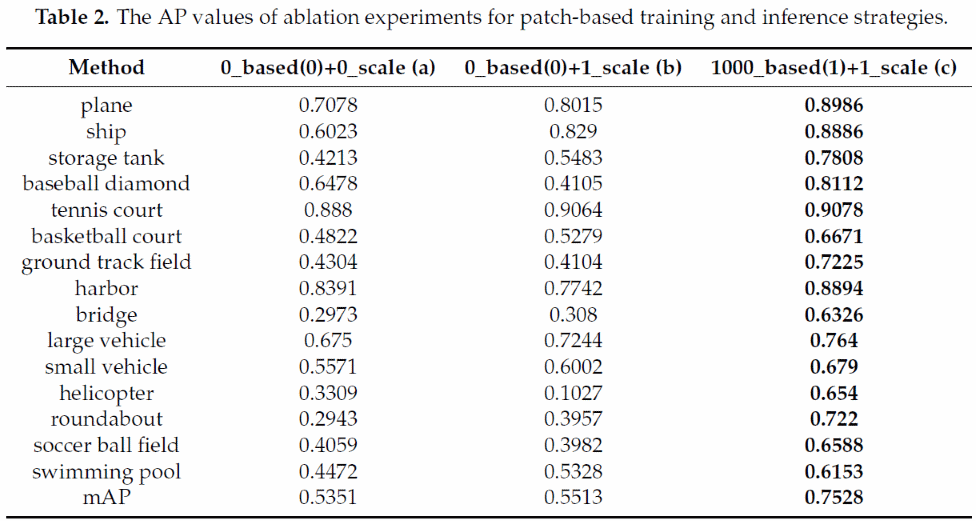
表2(a)采用原始影像进行训练。为了公平比较,我们将原始影像的大小缩放为1000×1000像素,并在原始影像上进行预测。表2(b)的训练策略与表2(a)相同,但对由原始影像获得的图块进行预测。表2(c)对由原始影像获得的图块进行训练和预测。对比表2(a)和表2(b)可以看出,基于图块的预测策略提高了大部分类别的检测精度。由于采用了基于图块的训练策略,表2(c)显示了巨大的优越性,它不仅在mAP上有压倒性的优势,同时每个类别的检测结果也得到了提升,这说明基于图块的训练策略具有针对性同时能更充分地挖掘目标的特征。此外,基于图块的训练策略在一定程度上增加了每个类别的样本数量,这将有助于提升样本稀缺类别的检测精度。
3.2.2 多尺度训练数据和训练过程中使用的多尺度图像尺寸策略
多尺度训练数据包括原始图像、基于原始图像、放大和缩小图像获取的图块。训练中使用的多尺度尺寸是指将一张影像或图块在送入网络之前,从指定的范围内随机缩放到一个尺度,每个尺度是图像或图块最短边的像素大小。为了验证多尺度训练数据和训练过程中使用的多尺度尺寸策略的重要性,我们进行了相关的对比实验,结果如表4所示:
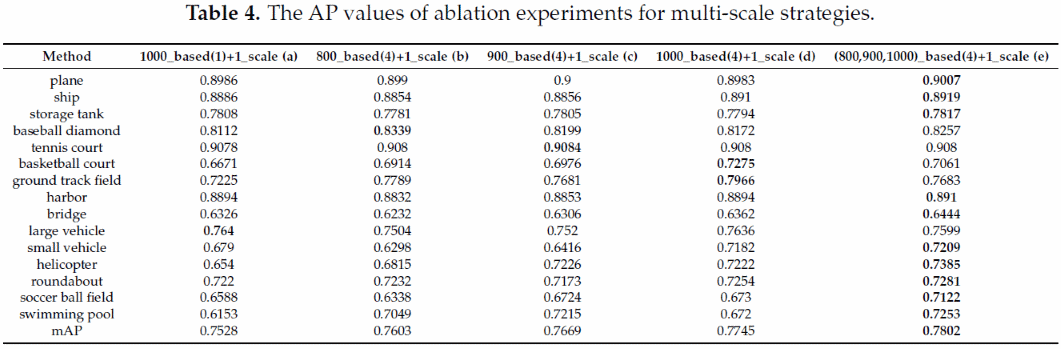
结合表4(a)和表4(d),我们可以发现,多尺度训练数据确实可以提高目标检测精度(0.7528到0.7745),特别是对于大尺寸类别如篮球场(0.6671到0.7275)、操场(0.7225到0.7966)以及样本稀缺类别如直升机(0.654到0.7222)等目标。表4(e)的精度高于表4(b)-(d),说明多尺度训练尺寸有助于提高精度。表4(b)-(d)的对比表明,训练图像的尺寸越大,检测的平均精度越高。
3.2.3 多尺度预测和ACNMS策略
多尺度预测策略包括同时在原始图像、缩小图像、水平旋转图像和垂直旋转图像上进行预测。对于以船舶、大型车辆和小型车辆为主的尺寸较小而密集度较大的物体,我们根据它们的CI适当增加NMS阈值。通用的NMS阈值为0.3,而ACNMS阈值为0.38。结果如表6所示,
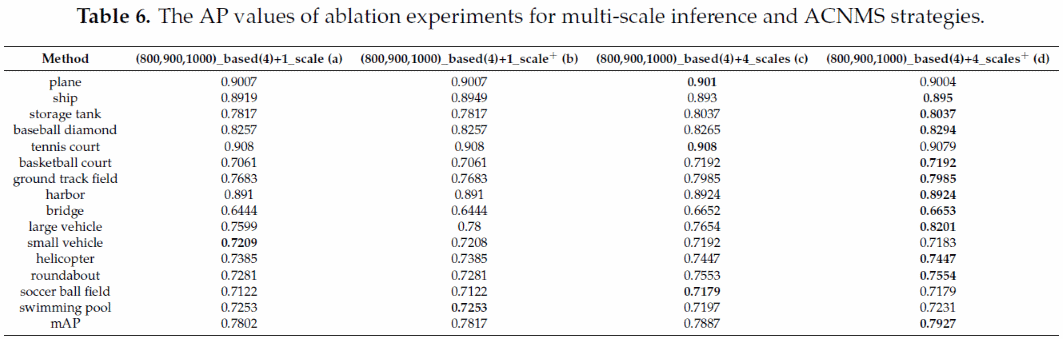
表6(b)、(d)中右上角的“+”表示我们采用了ACNMS策略。通过表6(a)与表6(c)、表6(b)和表6(d)的比较,说明了多尺度预测策略的有效性,储罐、操场、转盘等大、小目标的检测性能都得到了提高。表6(a)和表6(b)、表6(c)和表6(d)的比较说明了ACNMS策略的有效性。由于船舶、大型车辆和小型车辆的CI远远大于其他目标,因此我们略微提高了它们的NMS阈值。其中,船舶AP值在两次对比实验中分别增加0.003和0.002,大型车辆AP值分别增加0.002和0.0055,小型车辆AP值基本保持不变。相关实验表明,根据类别密集度增加NMS阈值确实可以提高检测精度。
3.3 外部对比实验
在DOTA验证数据集上,我们将DM-FPN与其他基于区域的目标检测网络进行了比较,主要包括Faster R-CNN和FPN。所选择的网络具有与我们相同的实验设置,但没有采用多尺度训练、预测和ACNMS策略。表8显示了不同的目标检测网络在DOTA验证数据集上的检测结果。
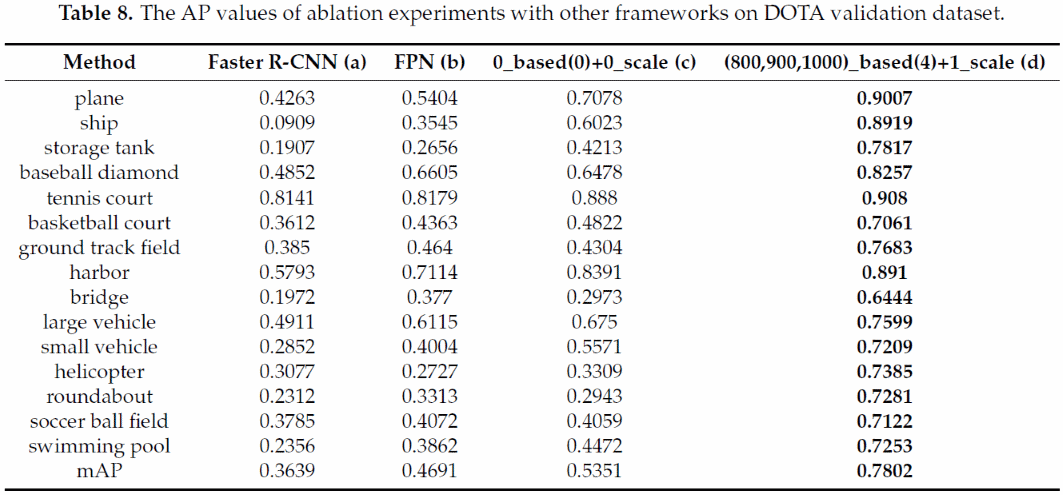
Faster R-CNN、FPN和表8(c)采用原始影像进行训练和预测。DM-FPN在每个类别的AP和mAP值上都具有压倒性的优势。表8(c)的mAP比Faster R-CNN高0.1712,比FPN高0.066,说明了该网络的优越性。表8(d)的mAP比Faster R-CNN的mAP高0.4163,比FPN的mAP高0.3111,比表8(c)的mAP高0.2451,说明了所提出的网络以及多尺度训练、预测和ACNMS策略的巨大优势。该框架在舰船、大型车辆、小型车辆、储罐等尺寸较小而密集度较大的目标检测中具有很大的优势。对直升机、转盘等样本稀缺目标的检测精度也有了较大的提高。DM-FPN在验证集上的检测结果如图2所示。

3.4 测试集对比实验
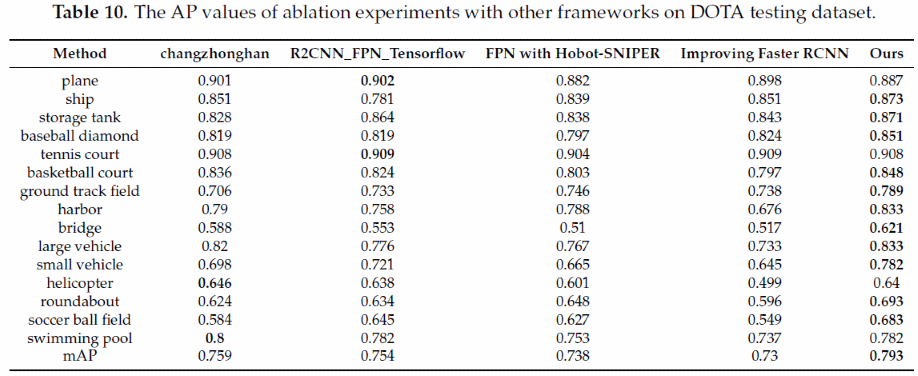
我们将基于测试数据集的检测结果提交到DOTA评估服务器,以验证DM-FPN的有效性。表10显示了目前检测表现较好的几组结果,DM-FPN取得了最好的检测结果(我们的结果在Task 2中被命名为“CVEO”,mAP为0.793)。其中,DM-FPN在11个类别的AP值都比其他几组结果要高,尤其是船舶、小型车辆、大型车辆和游泳池等目标,说明DM-FPN在尺寸较小而密集度较大的目标上检测性能更好。此外,一些大尺寸目标如港口和操场也比其他框架取得了更高的AP,这进一步证明了DM-FPN在大、小尺寸目标上都能取得更好的检测效果。
DOTA测试数据集的检测结果如图3所示。

4.讨论
本文采用DOTA数据集对提出的DM-FPN进行训练、验证和测试,在RGB三通道超高分辨率光学遥感图像的目标检测中取得了较好的效果。DOTA数据集是目前遥感图像中样本数量最大的目标检测数据集,它包含了15个常用类别的超高分辨率航空遥感图像。训练数据集的空间分辨率范围0.1~5米,我们的框架在这个影像空间分辨率范围内实现了更好的性能。为了显示整体的检测效果,我们在完整的图像进行了预测,结果如图4所示。

训练后的网络在检测现有的15个类别时表现得更好。然而,对于训练数据集中没有出现的类别或场景,如在雪地上的飞机或直升机,其检测效果并不理想。这也是所有深度学习框架的共同问题。如果提供足够的训练样本,仍有希望解决这一问题。
5.结论
针对高空间分辨率遥感影像中小而密集的目标检测问题,本文提出了一种有效的基于区域的目标检测框架DM-FPN,该框架充分利用了弱空间分辨率、强语义特征和高空间分辨率、弱语义的特征。同时,针对遥感影像像尺寸过大、影像背景复杂、训练样本大小和数量分布不均匀等问题,提出了多尺度训练、预测和自适应类别非极大值抑制策略。本文采用DOTA数据集对提出的DM-FPN进行训练、验证和测试,在验证集和测试集上均取得了优异的表现。在未来的研究工作中,我们将提高框架在检测速度和精度方面的性能,从而构建一个检测速度更快、更准确的高分辨率遥感影像目标检测网络。同时,在本文的基础上,我们将会开展旋转边界框目标检测的研究。
如何引用本文: